What's inside...
Huge workspace (6GB) + long build time (6 hours) + many post-build steps (17) = huge consumption of resources. Replicate the build? Share the workspace? Clone the workspace? Clone and share the workspace?
Background
Recently I was challenged with the opportunity to convert a large project (1,600,000+ LOC) from a commercial build system to Hudson as part of an enterprise-wide effort of a client to standardize their build environment. Without getting into the details of the project itself, one of the greatest challenges was overcoming the size of the source code repository as well as the length of the integration build, 6GB and 6 hours, respectively. The entire build process, including post-build scanning and reporting (Findbugs, Fortify, etc.) took over 12 hours.
Huge workspace (6GB) + long build time (6 hours) + many post-build steps (17) = huge consumption of resources. Replicate the build? Share the workspace? Clone the workspace? Clone and share the workspace?
Background
Recently I was challenged with the opportunity to convert a large project (1,600,000+ LOC) from a commercial build system to Hudson as part of an enterprise-wide effort of a client to standardize their build environment. Without getting into the details of the project itself, one of the greatest challenges was overcoming the size of the source code repository as well as the length of the integration build, 6GB and 6 hours, respectively. The entire build process, including post-build scanning and reporting (Findbugs, Fortify, etc.) took over 12 hours.
One of the primary objectives of this particular conversion was to reduce the time for overall throughput of the build process. An additional requirement was the publication of Sonar analysis reports for management consumption. And since each sub-project is autonomous in the reporting scheme, we needed to run the Sonar analysis on each of the 16 sub-projects as well.
Let's get started...
Let's get started...
I started by adding 17 steps to the build job, one for each sub-project as well as one for the entire project as a whole. But we were experiencing intermittent errors in the Sonar analysis steps which basically aborted the entire process. And aborting the entire process meant no publication of build statistics, etc., to the Hudson dashboard even though the build itself was completing successfully.
Share the workspace...
So we decided to create individual Hudson jobs for each of the Sonar analysis steps so that if one analysis step (job) failed, the others would run. And more importantly, the build job itself would complete publishing its code coverage and test results reports to the Hudson dashboards. But since we didn’t want to propagate a 6GB workspace for each of the 17 Sonar analysis jobs, not to mention the time required to repeatedly download the 1.6M LOC, we decided to use the ‘Custom workspace’ Advanced Project configuration option to point back to the main build job’s Hudson workspace. It worked.
All well and good… so we thought.
And now the nightly build process was taking 14 hours. Granted Sonar analysis was added to the process, but one of the goals was to reduce the overall throughput time, not increase it. And with the implementation of the 17 additional Sonar analysis jobs that are required to run on the same slave because of re-using the main build’s Hudson workspace, we needed to “pin” all the jobs to the same slave. Even though I was testing this prototype process on a single slave, we wanted the capability to run this process on any slave of a Hudson master that was equipped to handle the build. We also wanted the capability to distribute the workload of the 17 Sonar analysis jobs across the slaves, effectively reducing the overall build process throughput time.
Zip and copy...
So my next challenge was to develop an architecture that would solve two problems that were introduced by the new implementation; namely, increased overall throughput, and pinning all jobs to a single slave. First I experimented with zipping up the workspace in a post-build step of the main build, archiving it, and then in the downstream Sonar analysis job, using the ‘Copy artifacts from another project’ build step to bring it into the workspace and then a build step to unzip it.
The main build job would sometimes fail zipping up the huge workspace. But most often the downstream job would fail either retrieving the archive across the network or unzipping the archive because it was sometimes corrupted (probably from the download failing). It was very error prone and inconsistent, presumably because of the huge workspace. I experimented with the CopyArchiver, Copy Artifact, Copy Data to Workspace, and Copy to Slave plug-ins, but I finally abandoned the zip-and-copy idea never getting the entire process to run successfully from start to finish.
Ok, how about cloning?
Ok, how about cloning?
I then discovered the Clone Workspace SCM plug-in that, in theory, would allow us to run the main integration build on any capable slave, clone its workspace, and then run the downstream jobs on any other capable slave using the ‘cloned’ workspace. Essentially, this was the same as my zip-archive-unzip process, but all supported through a Hudson plug-in, not via a hacked-up process.

This insures the workspace is not archived if the build fails preventing wasted space since the downstream job is not triggered if the build fails. When the archiver finishes archiving the workspace successfully, it automatically deletes the previous workspace archive.
I then reconfigured each of the downstream analysis jobs to specify the ‘Clone Workspace’ Source Code Management configuration option also specifying the ‘Most Recent Not Failed Build’ criteria to match the parent job specification:

But… the proverbial good news, bad news.
The good news is that it recreates the workspace of the upstream job in the pre-build process as the Hudson workspace of the downstream job prior to running any build steps. The workspace of the downstream job is identical to the workspace of the main build upstream job. The bad news is that it recreates the workspace of the upstream job in the pre-build process as the Hudson workspace of the downstream job prior to running any build steps. (Yes- that’s not a typo- they are the same.)
The good news is that it recreates the workspace of the upstream job in the pre-build process as the Hudson workspace of the downstream job prior to running any build steps. The workspace of the downstream job is identical to the workspace of the main build upstream job. The bad news is that it recreates the workspace of the upstream job in the pre-build process as the Hudson workspace of the downstream job prior to running any build steps. (Yes- that’s not a typo- they are the same.)
Even though we consider it temporary (it is replaced on each execution of the downstream job), the workspace cannot be automatically removed when the job is finished remaining on the slave tying up valuable disk storage. We attempted to use the ‘CleanUp all other workspaces on the same slavegroup’ Hudson Build Environment option, but it did not do what we expected.
So now we had a new challenge. Even though we could now run the 17 downstream jobs independently of the main build job, i.e., on any capable slave, we added another problem to the list; lack of disk storage. In propagating the 6GB workspace 17 times, we had quickly consumed all available disk space on the slave. And in the future when we intend to utilize more than one slave, we could potentially have 18 6GB workspaces on each slave.
Ok, how about cloning AND sharing?
After a sudden stroke of brilliance (he said sarcastically), I finally came up with what would be our final solution. While implementing, revising, and testing it, I kept asking myself, “Why didn’t I think of this before?” It was a relatively simple solution, combining both previously thought-of theories, using the ‘Custom workspace’ Advanced Project option as well as the Clone Workspace SCM plug-in. The challenge was fine-tuning it so it would work.
To test my new architecture I was given three slaves that we prepared identically capable of running the main integration build. I created three Hudson jobs, one for each of the three slaves, to create a custom workspace using the cloned workspace of the main build job. The important difference between this configuration and the configuration of the previous Sonar analysis jobs that were also using the cloned workspace from the main integration build is that the workspace of each of these three jobs, which we call the ‘unarchive’ jobs for clarity, is a custom workspace named identically in each of the jobs. This is key. It is not a Hudson-created workspace (which contains the name of the job) as with the previous Sonar analysis jobs.
Each of the jobs, each pinned to a single slave, creates a X:\Hudson\workspace\AcmeMainProject as a custom workspace. The custom workspace is specified in the Advanced Project Options section:

After the three unarchive jobs have finished executing, each of the slaves has an identically named workspace with identical content.
I then reconfigured each of the downstream Sonar analysis jobs to use the workspace created by the unarchive jobs, X:\Hudson\workspace\AcmeMainProject, as a custom workspace and replaced the ‘Clone workspace’ SCM option with ‘None’. The result is that any of the analysis jobs can run on any of the three slaves since each of the three slaves has an identical workspace at the X:\Hudson\workspace\AcmeMainProject location.
Some final tuning...
Some final tuning...
After some trial and error and understanding that Hudson groups all jobs to be triggered alphabetically before triggering them regardless of how they are grouped in the triggering job, I finally developed an architecture of cascading jobs that would give us the capability we needed with a relatively minimal amount of disk storage as well as reduced the overall throughput time.
The main build job runs the 6-hour Ant build to produce the artifacts of the project. Upon successful completion, a single downstream job is triggered. That single downstream job does nothing more than trigger the three unarchive jobs as well as a fourth ‘trigger’ job. Using the combination of job names and job priorities, the three unarchive jobs run first, one on each capable slave, creating the custom workspace on each slave. The trigger job runs next because of a lower priority, on any of the slaves, and also does nothing more than trigger the 17 Sonar analysis jobs, the Findbugs job, and the Fortify analysis job. The downstream jobs are then released and run in alphabetical sequence within priority on any of the three slaves.
Using the Priority Sorter plug-in, I assigned declining priorities to the jobs reflecting the sequence in which they must run: 100 for the unarchive jobs, 75 to the trigger job, 50 to the Sonar analysis jobs, and 25 to the Findbugs and Fortify analysis jobs.
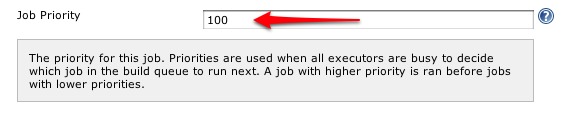
This guarantees that if all or any one of the slaves are(is) not available (either offline or another job is running on the slave) when the unarchive jobs are triggered, the unarchive jobs will execute prior to any of the downstream analysis jobs when the slave(s) again become(s) available.
So what was the bottom line, you ask?
Stem to stern including archiving and unarchiving the cloned workspace, the total throughput time of the entire build process (when all three slaves are available) was reduced from over 14 hours to just over 8 hours. Not only did we reduce the overall throughput time, we also reduced the total disk storage required by sharing the cloned workspaces.
Stem to stern including archiving and unarchiving the cloned workspace, the total throughput time of the entire build process (when all three slaves are available) was reduced from over 14 hours to just over 8 hours. Not only did we reduce the overall throughput time, we also reduced the total disk storage required by sharing the cloned workspaces.
Mission accomplished.